FAIR is possible! Increasing FAIR maturity of the Nordic and Baltic research data repositories
During the three years of the EOSC-Nordic project, we have tracked the FAIR maturity of the Nordic and Baltic research data repositories. The results have been reported in two deliverables: D4.1 An assessment of FAIR-uptake among regional digital repositories in August 2020, and the recently published D4.3 Report on Nordic and Baltic repositories and their uptake of FAIR. This article outlines the results and summarises the EOSC-Nordic’s FAIR evaluation journey.
Overall, evaluating and assessing the FAIRness of digital objects or data repositories is still a relatively new and evolving topic. The FAIR principles were published in 2016, and RDA’s FAIR Data Maturity Model emerged in 2020. When the EOSC-Nordic project started in late 2019, most FAIR evaluation frameworks were manual questionnaires or checklists, and studies exploring the FAIRness of repositories were based on manual collecting of information. From early on in the project, we realised that our study would require having an automated, machine-actionable method since we wanted to track the development of FAIR maturity in a measurable way in the Nordic and Baltic regions. We needed to create a well-defined method for it to be executed and repeated consistently during the project. This EOSC-Nordic approach and execution of a systematic, automated study of FAIR scores appeared to be unique and a first.
Our sample consists of 98 repositories associated with one or more of the Nordic/Baltic countries. The FAIR evaluation of each repository is based on typically ten randomly selected metadata records from their holdings. We streamlined the evaluation process by having a separate deployment of the evaluator tool with a user interface implemented in GoogleSheets and a pool of separate processor scripts that were set up in the Estonian Scientific Computing Infrastructure (ETAIS) cloud. When we began our work in early 2020, we used the FAIR Evaluator, which was, at that time, the only tool that provided automated evaluations.
In August 2020, we published our first results in the aforementioned D4.1. Overall, most of the repositories scored pretty low, meaning they did not have a lot of machine-actionable metadata. However, we were happy to note that there were repositories with relatively high scores, the highest being 72%. Between January and August 2020, we repeated our assessment six times and could see a rise in the average FAIR score from 30% to 35%. Even though we knew that some repositories had significantly increased the FAIRness of their metadata during this period, a closer examination revealed that most of the detected FAIR score differences were due to changes in the test indicators and the FAIR Evaluator tool.
A somewhat alarming finding was that we could not evaluate approximately 25% of the repositories due to the lack of GUIDs (Globally Unique IDentifier). This means that a fourth of the repositories do not identify each individual (meta)dataset using PIDs (Persistent IDentifier), URI (Uniform Resource Identifier), or other valid identification schemes that are essential for the (meta)data to be findable in the first place, by both humans and machines. The finding led us to organise a well-attended FAIRification webinar focusing on PIDs in November 2020. Link rot is a real problem: in our last evaluation round in 2022, approximately 6% of the metadata records were no longer found using the link collected only two years earlier.
During the autumn of 2020, we continued to experience inconsistencies in scoring and assessment of certain metrics. In addition, there was a lack of output to allow users to interpret and understand what was failing. At that point, we were asked by another Horizon 2020 project, FAIRsFAIR, to test out their FAIR evaluation tool called F-UJI. It had the flexibility to adapt batch runs and reports according to EOSC-Nordic’s needs. They reacted immediately to our feedback and suggestions, and the collaboration proved mutually beneficial. As a result, we executed our last evaluation with the FAIR Evaluator in May 2021, after which we used solely F-UJI. But as it was in active development, we also observed fluctuations in FAIR scores due to different versions of F-UJI. To minimise these variations, in July 2021, we fixed the version of F-UJI that we used to v135, which appeared to be stable.
Using F-UJI, the average FAIR score for repositories in the Nordics and Baltics was 22.5% in July 2021, and we saw an increase to 24.3% in April 2022. This can safely be assumed to reflect positive changes in the FAIRness of the metadata. It is worth noting that the F-UJI tool tends to give lower scores than the FAIR Evaluator.
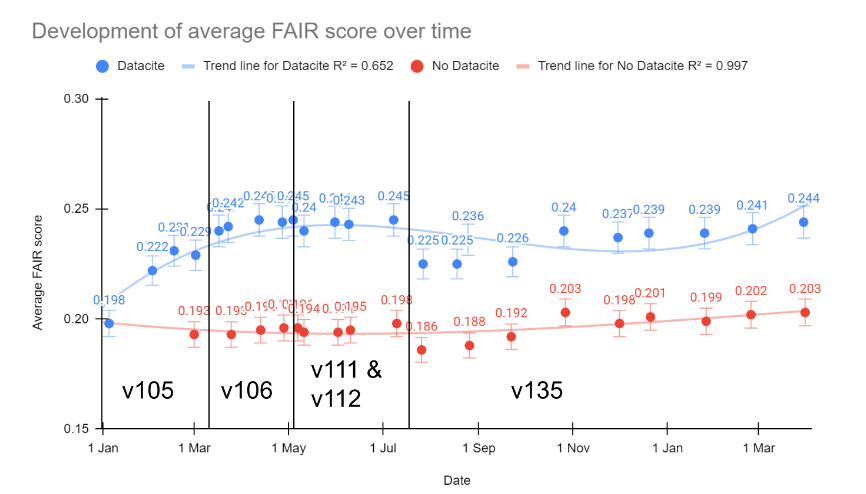
Figure 1: Development of average FAIR score of repositories over time
Unfortunately, a direct comparison of FAIR scores between these latest results and the early assessment rounds is not possible due to changes in the evaluation tools and the tool used. We will run our last FAIR score tests before the EOSC-Nordic Final Conference in October 2022, which will allow us 15 months to use the fixed version of the tool.
It has become evident during the project that there is strong support from the research community to strengthen FAIR and Open Science efforts. At the same time, it is clear that cultural changes take time and resources (see our report D4.4 report and recommendations on FAIR incentives and expected impacts in the Nordics, Baltics and EOSC). Comparison with other projects has led us to think that including many small repositories in our sample may have contributed significantly to the lowish scores. In addition, further analysis of individual repositories’ FAIR scores has shown that for most repositories, the FAIR score has stayed more or less unchanged between the test rounds. Repositories that run on established platforms (such as Dataverse, Figshare, and others) have noticeably higher FAIR scores, which are somewhat higher for CoreTrustSeal certified repositories.
Overall, there is much room for improvement and a need for hands-on work in implementing the FAIR principles. One of the key messages that we wish to convey is that FAIRification is entirely possible, and the time to start is now! Several repositories in our sample increased their FAIR scores notably during the project’s timeframe, and we’ve presented six encouraging case studies in our reports: Finnish Social Science Data Archive (FSD), Swedish National Data Service (SND), Bolin Centre Database, Qsar DataBase, Integrated Carbon Observation System (ICOS) and Icelandic Social Science Data Service (DATICE). FSD’s case is presented in D4.1, and their score increased from the initial 4/22 to 17/22 (using the FAIR Evaluator). The other five cases are presented in D4.3 and summarised in Figure 2.
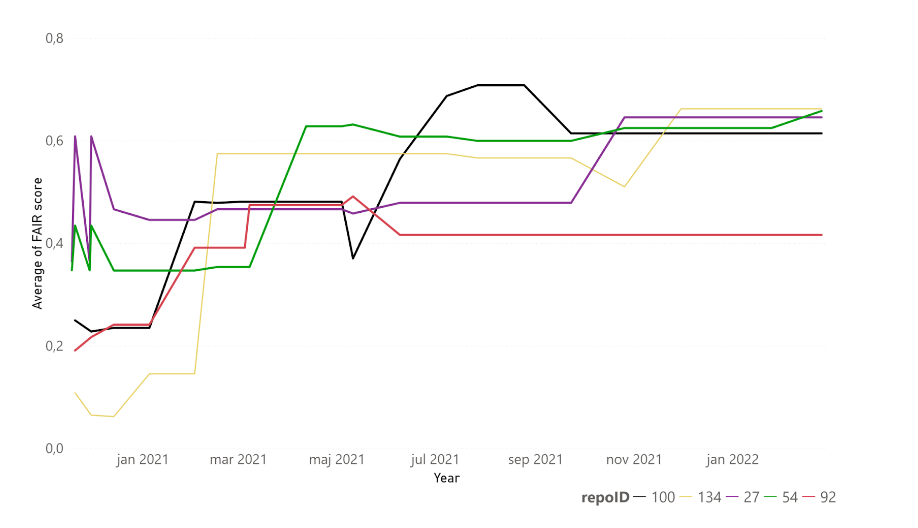
Figure 2: Evolution of FAIR score of selected repositories over time. Black: QsarDB (100), yellow: ICOS (134), purple: SND (27), green: Bolin Centre Database (54), red: DATICE (92).
Another key message is that calculating FAIR scores or assessing FAIR maturity levels of repositories is not a straightforward task. Many are averse to automated evaluations, claiming that what is tested is far too limited and that machine-actionability cannot be a requirement. Indeed, the FAIR scores should not be considered purely numerically, and test results should be carefully evaluated and interpreted. However, the aspect of machine-actionability is deeply embedded into FAIR principles. Indeed, FAIR will have little or no impact without the requirement of machine-actionability as a core driver in enabling sustainable and scalable data management. But everything has its pros and cons, and the FAIR metrics and assessment tools are no exception. In February 2022, we organised another well-attended and successful webinar to discuss the value and limitations of FAIR assessment tools. The presentations included several examples of how repositories could improve their FAIRness. It also became apparent that different evaluators do not give the same outcomes and that testing against concepts like “community standards” is not easy. The solution is to work together towards sharper criteria-setting and convergence in defining, articulating, and measuring the different FAIR components/metrics so that multiple evaluators will give more or less similar scores. The EOSC Task Force FAIR Metrics & Data Quality and an Apples-to-Apples group (engagement with the assessment tool developers to tease out the metadata gathering workflow) are currently addressing these ambiguities.
Our third key message is that FAIR assessments are an excellent tool for improving repository practices. Repositories can and should do self-assessments to recognise where they have gaps. For us in the EOSC-Nordic, the mass evaluation of FAIR scores was certainly a good starting point to figure out the biggest challenges and where to focus when assisting and supporting the repositories in their journey to FAIR. As a result, we have been able to raise awareness of FAIR principles in the Nordic and Baltic repositories and guided them through the technical challenges of making their (meta)data more FAIR. Interestingly, we noticed that the repositories with the highest FAIR scores, to begin with, were generally the most active ones in the webinars and were keen on improving their FAIR scores even more.
It is worth noting that a digital object cannot really be made FAIR or evaluated for FAIRness in isolation from its context – in our case, the data repository. For example, the persistence of an identifier is determined by the commitment of the organisation that assigns and manages it (see, e.g., L’Hours et al. 2020). Engaging directly with the research communities and repositories and presenting ways in which they can make progress on different aspects essential for the FAIR principles will, over time, leverage a change in FAIR research culture.
Read more about the FAIR uptake in the Nordics and Baltics from our reports. All materials from our webinars are available on the EOSC-Nordic Knowledge Hub.
Authors: Mari Kleemola (Finnish Social Science Data Archive), Hannah Mihai (DeiC), Josefine Nordling (CSC), and members of WP4 FAIR data.